이 글에서는 MPP DBMS 인 Greenplum 에 대해서 설명합니다.

Introduction To Greenplum Architecture
데이터베이스 관리 시스템의 발명은 효과적인 데이터 관리 및 쿼리에 대한 수요를 기반으로 합니다. 데이터베이스 관리 시스템이 있기 전에는 파일 기반 스토리지가 사용되었습니다. 다음 예에서 두 테이블은 바의 정보와 다른 바의 판매 정보를 나타냅니다. 이 두 가지 정보가 파일에 저장되어 있다면 두 개를 루프에 사용하여 각 매장의 맥주 판매량을 계산할 수 있습니다.
이 작업의 코드는 매우 짧지 만 알고리즘 복잡성은 매우 높습니다. 알고리즘의 낮은 효율성 외에도 파일 저장에 다른 문제가 있습니다:
데이터 일관성: 예를 들어 판매 기록에 해당하는 막대가 막대 파일에 나타나지 않아 유효하지 않은 데이터가 존재합니다;
레코드 수정: 특히 문자열 유형의 가변 길이 속성을 수정하면 유지 관리가 어려워집니다;
쿼리의 복잡성, 중복성 및 비효율성: 각 쿼리는 검색할 수 있는 프로그램을 작성해야 하며,검색 프로그램은 실행 시간과 공간에 큰 영향을 미칩니다;
기술 요구 사항이 높음
위에서 언급한 상황 외에도 많은 문제가 있습니다.

그래서 데이터베이스 관리 시스템이 탄생했습니다. 많은 사람들이 데이터베이스를 줄여서 데이터베이스 관리 시스템으로 사용합니다. 사실 데이터베이스와 데이터베이스 관리 시스템은 두 가지 개념입니다.
데이터베이스는 효율적인 저장 및 조회를 위해 효과적으로 구성되고 관련성이 있으며 편리한 데이터를 모아논 집합을 말합니다. 데이터베이스 관리 시스템은 일종의 소프트웨어로, 데이터베이스의 데이터를 관리하는 데 사용됩니다. 추가, 삭제 및 수정의 기본 인터페이스를 제공 할뿐만 아니라 효율적인 SQL과 같은 쿼리 언어도 제공 할 수 있습니다. 데이터 모델링의 경우 문서, 개체, Key Value 등을 기반으로하는 등 다양한 모델링 방법이 있으며, 기본 데이터 모델로 관계형 모델을 기반으로하는 데이터베이스 관리 시스템을 관계형 데이터베이스 관리 시스템이라고하며 Greenplum은 관계형 데이터베이스라고하는 일종의 관계형 데이터베이스 관리 시스템이기도합니다.
관계형 데이터베이스에는 데이터를 정의하고 저장하는 방법, 데이터 일관성, 트랜잭션 및 동시성 제어를 포함한 데이터 무결성을 보장하는 방법, 사용자 친화적인 쿼리 인터페이스를 지원하는 방법 등 몇 가지 중요한 기술적 사항이 있습니다.
Greenplum Overall Architecture
다음으로, 그린플럼이 위의 문제를 어떻게 해결하는지 살펴보겠습니다. 먼저 Greenplum의 전체 아키텍처를 살펴보겠습니다.
Greenplum은 Postgres 기반의 오픈소스 분산 데이터베이스입니다. 토폴로지 구조로 보면 독립형 Postgres로 구성된 데이터베이스 클러스터입니다. 하지만 여기에 국한되지 않습니다. 통합 데이터베이스 인터페이스를 제공하여 사용자가 독립형 데이터베이스를 사용하는 것과 같은 느낌을 받을 수 있으며, 클러스터 처리에 대한 최적화도 많이 이루어졌습니다.
물리적 토폴로지 측면에서 Greenplum 데이터베이스는 전형적인 마스터 세그먼트 구조이며, Greenplum 클러스터는 일반적으로 마스터 노드, 스탠바이 노드 및 여러 세그먼트 노드로 구성되며, 노드는 고속 네트워크를 통해 상호 연결됩니다. 마스터는 전체 데이터베이스의 입구입니다. 최종 사용자는 마스터에 접속하여 쿼리를 수행합니다. 스탠바이 마스터는 마스터에 대한 고가용성 지원을 제공합니다. 세그먼트 노드는 작업 노드이며, 데이터는 세그먼트에 존재합니다. 미러 세그먼트는 세그먼트에 대한 고가용성 지원을 제공합니다.
아래 그림의 각 박스는 물리 머신으로, 물리 머신의 최상의 성능을 얻기 위해 노드는 여러 세그먼트 프로세스를 유연하게 배포할 수 있습니다. 쿼리 프로세스에서 마스터 노드는 사용자가 시작한 쿼리문을 받으면 쿼리 컴파일, 쿼리 최적화 및 기타 작업을 수행하고 병렬 쿼리 계획을 생성한 후 실행을 위해 세그먼트 노드에 배포합니다. 세그먼트가 실행된 후 데이터는 마스터 노드로 다시 전송되어 최종적으로 사용자에게 표시됩니다.
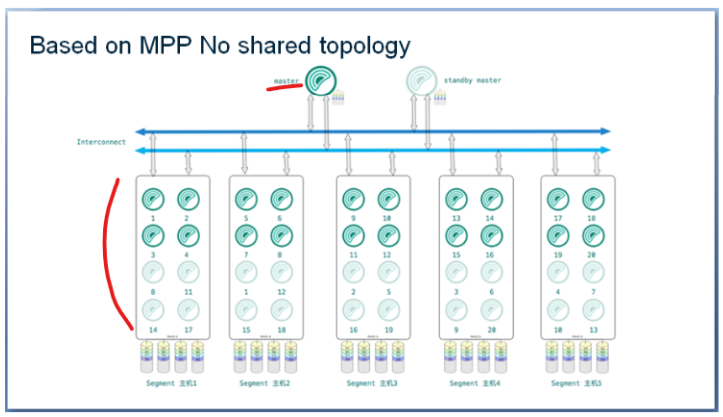
Greenplum의 아키텍처를 이해했다면 이제 데이터가 어떻게 저장되는지 살펴봅시다. Greenplum에서 각 물리적 머신은 여러 개의 디스크에 해당하고, 각 디스크는 물리적 디스크와 연결되며, 각 디스크에는 여러 개의 데이터 파티션이 있습니다. Greenplum의 데이터 구성은 다음과 같은 전략을 채택합니다.
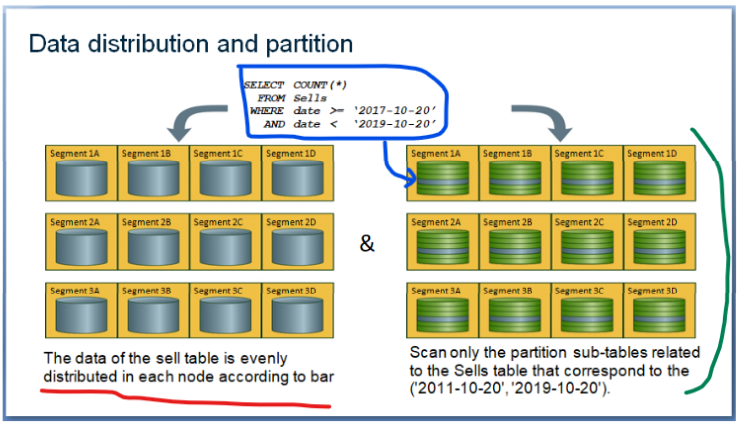
우선, 데이터는 설정된 배포 전략에 따라 각 세그먼트에 균등하게 배포됩니다. 그린플럼이 지원하는 배포 전략에는 해시 배포, 랜덤 배포, 그린플럼 6의 새로운 복제 배포 등이 있습니다. 이 작업을 데이터 조각화라고 합니다.
그런 다음 각 노드의 데이터에 대해 데이터 분할을 통해 노드의 데이터를 더 작은 하위 집합으로 분할하여 쿼리 시 비용을 낮출 수 있습니다. 이 작업을 데이터 파티셔닝이라고 합니다.
위의 '바'를 예로 들어 설명해 보겠습니다. 왼쪽은 데이터 조각화 처리입니다. Sells 테이블은 열('bar')에 따라 분할되고 여러 노드로 나뉩니다. 그런 다음 각 노드는 '날짜'에 따라 분할되어 작은 하위 테이블로 나뉩니다. 그림의 쿼리 문을 통해 그림의 파란색 부분만 스캔하여 쿼리 작업을 완료할 수 있으므로 데이터 스캔 양이 크게 줄어듭니다.
그린플럼의 서비스 프로세스를 살펴보겠습니다.
다음 예시에서는 왼쪽에 마스터 노드, 오른쪽에 세그먼트 노드 두 개가 있습니다. 토폴로지 관점에서 보면, Greenplum은 독립형 Postgres로 구성된 데이터베이스 클러스터입니다.
이 예제에는 세 개의 Postgres 프로세스가 있습니다. 클라이언트에 요청이 있을 때, 클라이언트는 Postgres의 libpq 프로토콜을 통해 Greenplum의 마스터 노드에 연결합니다. 마스터의 포스트마스터 프로세스(postmaster process)가 연결 요청을 수신한 후, 클라이언트의 모든 쿼리 요청을 처리하기 위해 서브 프로세스(QD)를 생성합니다. QD와 원본 마스터는 공유 메모리를 통해 데이터를 공유합니다.


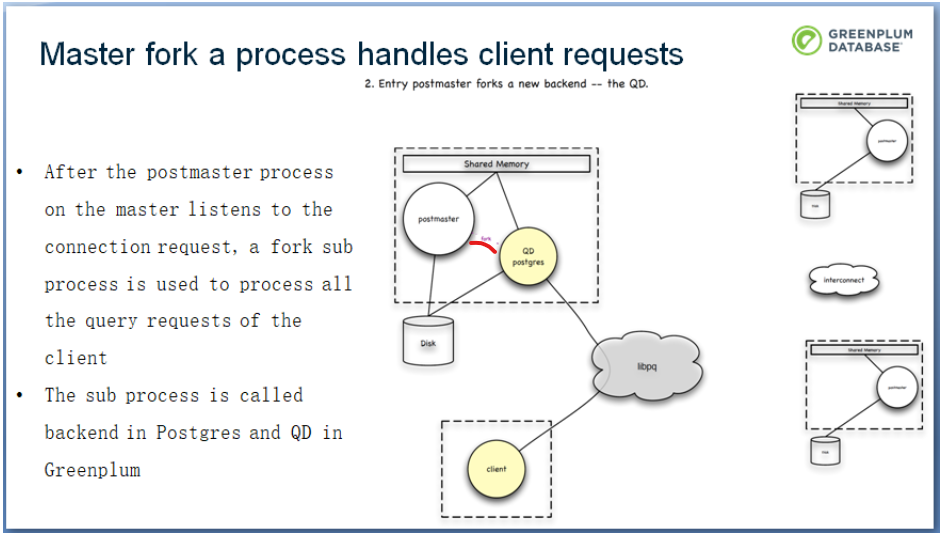
그런 다음 QD와 개별 세그먼트 간의 연결이 있습니다. QD는 각 세그먼트의 클라이언트로 볼 수 있으며, QD 프로세스는 모든 세그먼트 노드에 연결 요청을 보내고, libpq 프로토콜과 각 세그먼트를 통해 연결 요청을 설정하며, 세그먼트의 포스트마스터 프로세스는 QD 연결 요청을 수신하면 후속 쿼리 요청을 처리하기 위해 서브 프로세스(QE)를 생성하기도 합니다. QD의 정식 명칭은 쿼리 배포자인 쿼리 디스패처이고, QE는 쿼리를 처리하는 쿼리 실행자입니다. 모든 QD와 QE 프로세스는 함께 작동하여 클라이언트가 보낸 쿼리 요청을 완료합니다.
준비 작업이 완료된 후 쿼리는 어떻게 진행되나요?
클라이언트가 마스터의 QD 프로세스에 쿼리 요청을 보내면, QD 프로세스는 원본 쿼리문을 파싱하고, 옵티마이저를 통해 분산 쿼리 계획을 생성한 후, libpq 프로토콜을 통해 각 세그먼트의 QE 프로세스에 보내는 등 수신된 쿼리를 처리합니다. 각 세그먼트의 QD와 QES는 상호 연결을 설정합니다. 여기서 주의할 점은, Libpq는 주로 명령과 결과 반환을 제어하는 데 사용되며, 인터커넥트는 내부 데이터 통신에 사용된다는 점입니다.
The full name of QD is query dispatcher, which is a distributor, while QE is query executor, which processes queries. All QD and QE processes will work together to complete the query request sent by the client.


다음에 이어서 포스팅 하도록 하겠습니다.
원문 참고: https://greenplum.org/introduction-to-greenplum-architecture/










