Redis는 다양한 제품 옵션이 존재합니다. 공식 홈페이지에 있는 Redis products에 보면 Redis Cloud, Enterprise Software, Enterprise for Kubernetes, Insight 그리고 마지막으로 OSS and Stack이 존재합니다.

Table Of Contents
Redis OSS와 Stack 라이선스 (License)
레디스는 오픈소스 라이선스인 BSD 라이선스를 따르고 있었습니다. 하지만 2024년 레디스 7.4부터 향후 모든 버전의 레디스 소프트웨어에 RSAL2 (Redis Source Available License 2)와 SSLPv1 (Server Side Public License)라는 듀얼 라이선스를 적용하게 되었습니다.
더 자세한 사항은 다음 링크 확인해 보시면 되겠습니다.
어찌 되었든, Redis OSS와 Stack은 이러한 듀얼 라이선스를 적용한 레디스의 오픈 소스 제품입니다. 그러므로 레디스를 이용해서 서비스를 제공하는 클라우드 업체들은 무료로 사용할 수 없습니다.
하지만, 일반 개발자나 이 제품에 데이터를 저장해서 사용하던 사용자들은 해당 제품들을 설치해서 사용하는 것에 대한 제약이 존재하지 않습니다.
저는 일반 사용자이므로 Redis OSS를 통해 Redis Cluster를 구축해 보려고 합니다. Redis Cluster는 Redis OSS만 설치해도 사용 가능합니다.

Redis OSS와 Redis Stack의 차이는?
Redis Stack은 Redis를 사용할 때 유용한 확장팩으로 보실 수 있습니다. Redis Stack은 Redis OSS의 핵심 기능을 확장하고 디버깅 등을 위한 완벽한 개발자 환경을 제공하는 추가 확장 패키지입니다.
개발자가 밀리초 이내에 요청을 안정적으로 처리할 수 있는 백엔드 데이터 플랫폼으로 실시간 애플리케이션을 구축할 수 있도록 Redis Stack이 만들어졌습니다. Redis Stack은 기존 Redis OSS를 핵심으로 삼아 최신 데이터 모델, 데이터 처리 도구로 개선하고 복잡한 처리를 하는 기능을 포함합니다.
궁극적으로 Redis Stack의 목표는 단순성, 성능, 안정성이라는 Redis OSS의 철학을 지속적으로 충족하는 실시간 데이터 플랫폼을 구축하는 것입니다.

Redis Stack은 Redis OSS의 주요 기능에서 제공하는 모든 최신 기능을 제공함으로써 Redis의 개발자 환경을 통합하고 간소화합니다. Redis Stack은 다음과 같은 기능을 Redis에 추가로 제공합니다.
1. 확률적 데이터 구조
2. 쿼리 가능한 JSON 문서
3. 해시 및 JSON 문서 전반에 걸친 쿼리
4. 전체 텍스트 검색을 포함한 시계열 데이터 지원(수집 및 쿼리)
Redis 인스턴스의 종류
Redis는 단순한 standalone의 simple database부터 HA만 지원하거나, Clustered database 혹은 HA clustered database를 모두 지원합니다.
구성 적으로 보면 다음 그림과 같습니다.

Redis 클러스터란?
Redis 클러스터는 데이터가 여러 Redis 노드에 자동으로 샤딩되는 Redis 설치를 실행할 수 있는 방법을 제공합니다. 또한 Redis Cluster는 파티션 중에도 어느 정도의 가용성, 즉 일부 노드가 실패하거나 통신할 수 없는 경우에도 작업을 계속할 수 있는 기능을 제공합니다. 그러나 더 큰 장애가 발생하는 경우(예: 대부분의 마스터를 사용할 수 없는 경우) 클러스터를 사용할 수 없게 됩니다.
Redis Cluster는 Redis OSS를 설치해서 사용하실 수 있습니다.
따라서 Redis Cluster를 사용하면 다음과 같은 기능을 사용할 수 있습니다:
- 데이터 세트를 여러 노드에 자동으로 분할합니다.(샤딩)
- 노드에 장애가 발생하거나 나머지 클러스터와 통신할 수 없는 경우에도 부분 작업을 계속 진행합니다.(고가용성)
- Slave노드를 통해 가용성을 유지합니다. (고가용성)

Redis 클러스터 TCP 포트
모든 Redis 클러스터 노드에는 클라이언트에 서비스를 제공하는 데 사용되는 Redis TCP 포트(default: 6379)와 클러스터 버스 포트라고 하는 두 번째 포트, 즉 두 개의 열린 TCP 연결이 필요합니다. 기본적으로 클러스터 버스 포트는 데이터 포트에 10000을 추가하여 설정되지만( default : 16379), 클러스터 포트 구성에서 이를 재정의할 수 있습니다.
클러스터 버스는 바이너리 프로토콜을 사용하는 노드 간 통신 채널로, 대역폭과 처리 시간이 짧아 노드 간 정보 교환에 더 적합합니다. 노드는 장애 감지, 구성 업데이트, 장애 조치 승인 등을 위해 클러스터 버스를 사용합니다. 클라이언트는 클러스터 버스 포트와 통신을 시도해서는 안 되며, Redis 명령 포트를 사용해야 합니다. 그러나 방화벽에서 두 포트를 모두 열어야 하며, 그렇지 않으면 Redis 클러스터 노드가 통신할 수 없습니다.
Redis 클러스터가 제대로 동작하기 위해서 각 노드마다 아래의 통신 조건이 필요합니다.
- 클라이언트와 통신하는 데 사용되는 클라이언트 통신 포트(일반적으로 6379)는 클러스터에 도달해야 하는 모든 클라이언트와 키 마이그레이션을 위해 사용합니다.
- 클라이언트 포트를 사용하는 다른 모든 클러스터 노드에 대해 열려 있어야 합니다.
- 클러스터 버스 포트는 다른 모든 클러스터 노드에서 연결할 수 있어야 합니다.
Redis 클러스터 데이터 샤딩
Redis Cluster는 일관된 해싱을 사용하지 않고 모든 키가 개념적으로 해시 슬롯의 일부인 다른 형태의 샤딩을 사용합니다.
Redis Cluster에는 16384개의 해시 슬롯이 있으며, 주어진 키의 해시 슬롯을 계산하려면 키 모듈 16384의 CRC16을 구하면 됩니다.
Redis 클러스터의 모든 노드는 해시 슬롯의 하위 집합을 담당하므로, 예를 들어 노드가 3개인 클러스터가 있을 수 있습니다.
- 노드 A는 0에서 5500까지의 해시 슬롯을 포함합니다.
- 노드 B에는 5501에서 11000까지의 해시 슬롯이 있습니다.
- 노드 C는 11001에서 16383까지의 해시 슬롯을 포함합니다.
이렇게 하면 클러스터 노드를 추가하고 제거할 때 데이터 이동이 용이합니다. 예를 들어 새 노드 D를 추가하려면 노드 A, B, C의 일부 해시 슬롯을 D로 이동해야 합니다. 마찬가지로 클러스터에서 노드 A를 제거하려면 A가 제공하는 해시 슬롯을 B와 C로 이동한 후, 노드 A가 비어 있으면 클러스터에서 완전히 제거할 수 있습니다.

노드에서 다른 노드로 해시 슬롯을 이동해도 작업을 중단할 필요가 없으므로 노드를 추가 및 제거하거나 노드가 보유한 해시 슬롯의 비율을 변경해도 가동 중단 시간이 필요하지 않습니다.
여러 키를 위한 해시 태그 지원
Redis Cluster는 단일 명령 실행(또는 전체 트랜잭션 또는 Lua 스크립트 실행)에 관련된 모든 키가 동일한 해시 슬롯에 속하는 한 다중 키 작업을 지원합니다. 사용자는 해시 태그라는 기능을 사용하여 여러 키를 동일한 해시 슬롯에 속하도록 강제할 수 있습니다.
해시 태그는 Redis 클러스터 사양에 문서화되어 있지만, 키의 {} 괄호 사이에 하위 문자열이 있는 경우 문자열 안에 있는 내용만 해시된다는 것이 요점입니다. 예를 들어, user:{123}:profile 및 user:{123}:account 키는 동일한 해시 태그를 공유하기 때문에 동일한 해시 슬롯에 있는 것이 보장됩니다. 따라서 동일한 다중 키 작업에서 이 두 키에 대해 작업할 수 있습니다.
Redis Cluster Master-Replica 모델
마스터 노드의 하위 집합에 장애가 발생하거나 대부분의 노드와 통신할 수 없는 경우에도 가용성을 유지하기 위해 Redis Cluster는 모든 해시 슬롯에 1(마스터 자체)에서 N개의 복제본(N-1개의 추가 복제본 노드)이 있는 마스터-복제본 모델을 사용하며, 이 모델에는 마스터와 복제본 노드가 있습니다.
노드 A, B, C가 있는 예제 클러스터에서 노드 B에 장애가 발생하면 5501-11000 범위의 해시 슬롯을 더 이상 제공할 방법이 없기 때문에 클러스터를 계속할 수 없습니다.
그러나 클러스터가 생성될 때(또는 나중에) 모든 마스터에 복제 노드를 추가하여 최종 클러스터가 마스터 노드인 A, B, C와 복제 노드인 A1, B1, C1로 구성되도록 합니다. 이렇게 하면 노드 B에 장애가 발생해도 시스템이 계속 작동할 수 있습니다.

노드 B1이 B를 복제하고 B에 장애가 발생하면 클러스터는 노드 B1을 새 마스터로 승격하여 계속 정상적으로 작동합니다.
그러나 노드 B와 B1, B2가 동시에 장애가 발생하면 Redis 클러스터는 계속 작동할 수 없습니다.
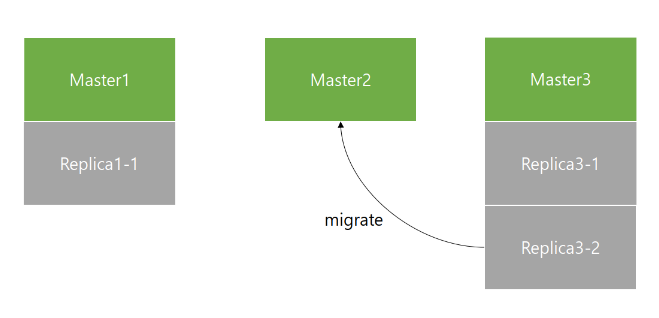
이런 상황을 대비하여 Redis cluster는 replica migration을 제공합니다.
replica migration은 replica가 부족한 master에게 replica가 더 많은 master의 replica를 옮겨주는 것을 말합니다.
아래 그림에서 Master2는 Replica가 없으므로, Replica가 두 개 있는 Master3로부터 하나의 Replica를 migration 할 수 있습니다.
Redis 클러스터 구성 매개변수
이제 클러스터 배포 예제를 만들어 보겠습니다. 계속하기 전에 Redis 클러스터가 redis.conf 파일에 도입하는 구성 매개 변수를 소개하겠습니다.
- cluster-enabled <yes/no>: yes인 경우, 특정 Redis 인스턴스에서 Redis 클러스터 지원을 활성화합니다. 그렇지 않으면 인스턴스는 평소와 같이 독립형 인스턴스로 시작됩니다.
- cluster-config-file <파일명>: 이 옵션에 기록된 파일은 사용자가 편집할 수 있는 구성 파일이 아니라 Redis 클러스터 노드가 변경 사항이 있을 때마다 클러스터 구성(기본적으로 상태)을 자동으로 유지하여 시작 시 다시 읽을 수 있도록 하는 파일입니다. 이 파일에는 클러스터의 다른 노드, 해당 노드의 상태, 영구 변수 등이 나열됩니다. 종종 이 파일은 일부 메시지 수신의 결과로 다시 작성되어 디스크에 플러시 됩니다.
- cluster-node-timeout <밀리초>: 장애로 간주하지 않고 Redis 클러스터 노드를 사용할 수 없는 최대 시간입니다. 지정된 시간 이상 마스터 노드에 연결할 수 없는 경우, 해당 복제본에 의해 마스터 노드가 페일오버됩니다. 이 매개변수는 Redis 클러스터에서 다른 중요한 것들을 제어합니다. 특히, 지정된 시간 동안 대부분의 마스터 노드에 연결할 수 없는 모든 노드는 쿼리 수락을 중단합니다.
- cluster-slave-validity-factor <factor>:
- 특정 시간 동안 master와 연결이 끊기 slave는 cluster에서 제외함
- 0으로 설정하면 복제본은 항상 자신을 유효한 것으로 간주하므로 마스터와 복제본 간의 링크 연결이 끊어진 시간에 관계없이 항상 마스터를 페일오버하려고 시도합니다.
- 양수인 경우
- 값이 양수이면 최대 연결 해제 시간은 노드 시간 초과 값에 이 옵션에 제공된 계수를 곱한 값으로 계산되며, 노드가 복제본인 경우 마스터와 연결이 지정된 시간 이상 연결 해제된 경우 페일오버를 시작하려고 시도하지 않습니다.
- 예를 들어 노드 시간제한을 5초로 설정하고 유효성 계수를 10으로 설정하면 마스터에서 50초 이상 연결이 끊긴 복제본은 마스터에 대한 장애 조치(failover)를 시도하지 않습니다. cluster-node-timeout: 5초 X factor 10초 = 50초
- cluster-migration-barrier <count>: 한 master가 유지해야 하는 최소 replica의 개수로 일부 replica는 이 값보다 적은 replica를 가진 master의 replica로 migration 할 수 있습니다.
- cluster-require-full-coverage <yes/no>: 이 옵션을 yes로 설정하면 기본적으로 클러스터는 키 공간의 일부가 노드에 포함되지 않는 경우 쓰기(write)를 중지합니다. 이 옵션을 no로 설정하면 키의 하위 집합에 대한 요청만 처리할 수 있는 경우에도 클러스터가 쿼리를 계속 처리합니다. 즉, no로 설정하면 특정 노드가 장애가 발생해도 나머지 노드만 동작합니다.
- cluster-allow-reads-when-down <yes/no>: 기본적으로 no로 설정하면, 노드가 마스터 쿼럼에 도달하지 못하거나 전체 커버리지가 충족되지 않는 등 클러스터가 실패로 표시되면 Redis 클러스터의 노드는 모든 트래픽에 대한 서비스를 중지합니다. 이렇게 하면 클러스터의 변경 사항을 인식하지 못하는 노드에서 잠재적으로 일관되지 않은 데이터를 읽는 것을 방지할 수 있습니다. 이 옵션을 yes로 설정하면 장애 상태에서도 노드에서 읽기를 허용할 수 있으므로 읽기 가용성의 우선순위를 정하되 일관성 없는 쓰기를 방지하려는 애플리케이션에 유용합니다. 또한 마스터에 장애가 발생했지만 자동 장애 복구가 불가능한 경우에도 노드가 계속 쓰기를 제공할 수 있으므로 한두 개의 샤드만 있는 Redis 클러스터를 사용하는 경우에도 사용할 수 있습니다.
오늘은 레디스 OSS와 Stack의 차이점과 Redis Cluster에 대한 개념에 대해서 알아보았습니다. 다음에는 실제 Redis Cluster를 구축하고 테스트하는 것을 알아보도록 하겠습니다.
'DBMS' 카테고리의 다른 글
| Redis Cluster 예제 app (ruby, python) (0) | 2024.05.30 |
|---|---|
| Redis Cluster 리눅스에 설치하고 테스트 하기 (0) | 2024.05.29 |
| 벡터 데이터베이스란 무엇이며 어떻게 동작하는지 알아보기 (임베딩, 인덱싱 등) (0) | 2024.05.21 |
| 레디스(Redis) 최신 매출 정보(2023)와 회사 규모 (0) | 2024.05.16 |
| HammerDB에서 Redis를 지원하는가?(HammerDB supports Redis ?) (0) | 2024.01.17 |










